目標先講清楚:
我要做一個「能看圖、會記憶」的智慧助理。
Input:語音/文字/圖片;Output:文字/語音。
並且要能即時互動(real-time)。
傳統輪詢式 API(請求→回應)遇到語音、長連線、多使用者很快會卡。
我需要的是低延遲、多模態、可長連線的體驗:講一句話、丟一張圖,助理就能立刻理解、回覆並持續「在線」。
我先把常見方案放在同一張圖表裡,比較定位、上手程度、可擴展性、費用四個面向:
| 面向 | OpenAI TTS/Realtime | Gemini Live API | LiveKit |
|---|---|---|---|
| 定位 / 模型相容性 | 官方 Realtime API(WebRTC/WebSocket) + TTS;直連 OpenAI 即時/音訊模型(如 gpt-realtime、GPT 家族)。 | Google 的即時多模態介面(WebRTC/WebSocket),鎖定 Gemini。 | 實時媒體基礎設施(SFU)+ Agents 框架;前後端提供 SDK;模型無關、可插換,官方支援「多家供應商/多款模型」。 |
| 上手程度 | 有 Realtime Quickstart,文件完整。 | 有官方文件參考;也可透過合作平台簡化媒體處理。 | 有 Agents(Node.js/Python) 與文件快速入門;需理解 RTC/房間/軌道 等概念。 |
| 費用 / 計費 | 依 token 計費(文字/音訊/影像有別;輸入/輸出分開計)。 | 有 免費層;付費同樣以 每百萬 token 計價。 | 框架開源,自建(OSS)不含模型費,但需自負基礎設施;LiveKit Cloud 依用量計價(代理會話分鐘、傳輸等)。 |
參考:OpenAI Realtime/TTS、Google Gemini Live API、LiveKit Docs 與 Pricing(文末附連結)
一句話:我希望媒體傳輸與多方即時連線交給專業的基礎設施,而模型層保持可插拔,之後要換 OpenAI/Gemini、或加上本地模型都不痛苦。
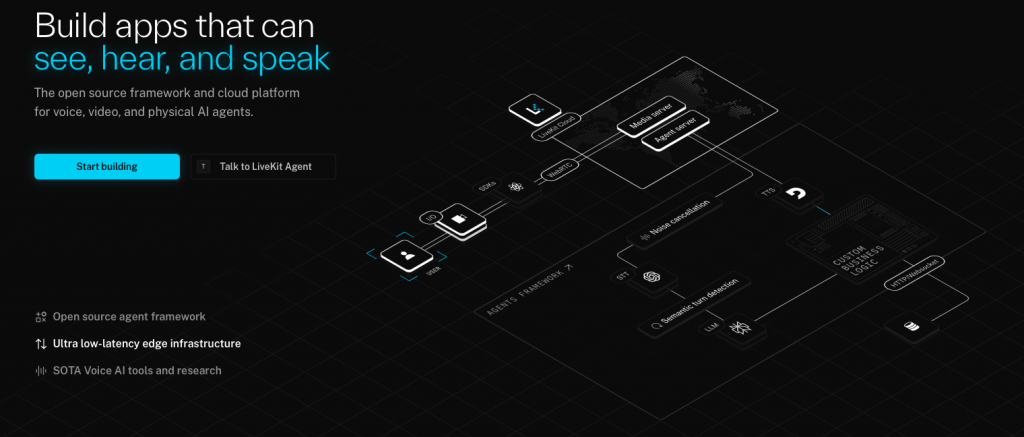
好處是:即時性與智能清楚分層,哪層要換都很乾淨。
跟著這支 YouTube 教學與示例程式碼,我用不到 50 行就做出第一個能說話的 Agent。
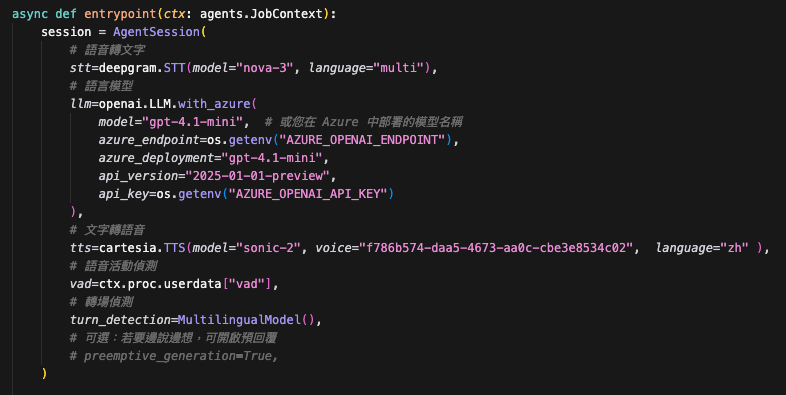
特別有感的是——LiveKit 的 Agents 框架把接口都開好了:
代碼截圖:
圖片理解(Vision)與記憶是兩個關鍵拼圖。
我會在現有骨架上加一個圖片理解模組,基本就完成 50% 的雛形。
Default(3/5)—— 用 LiveKit 替服務加上「圖片理解」功能。
把 Vision 接進既有語音互動流程,測一次完整體驗。
另:官方網站都持續更新,實際費率與可用模型以文件為準。